電子書籍/電子出版の今を知る、今が分かる
凸版のOCR技術、古典籍の「くずし字」を80%超の精度でテキストデータ化
今夏から、開発したOCR処理技術を使った古典籍のテキストデータ化サービスを試験的に開始する予定。
» 2015年07月06日 17時38分 公開
[eBook USER]
凸版印刷は7月3日、江戸期以前の古典籍に用いられた「くずし字」を高精度でテキストデータ化するOCR(光学文字認識)技術を開発したと発表した。

この技術は、同社が2013年から提供している「高精度全文テキスト化サービス」のテキストデータ化技術のシステム基盤をベースに、公立学校法人公立はこだて未来大学の寺沢憲吾准教授が開発した「文書画像検索システム」を組み合わせることで実現。
2014年度に実施した検証実験では、くずし字で記されている書物を80%以上の精度でOCR処理することに成功した。

技術開発の背景について凸版印刷は、「近年、大規模災害による資料アーカイブの必要性の見直しや、専門家の減少と資料の経年劣化による文化継承の危機的状況から、歴史的資料のデジタル化やテキストデータ化が求められているが、総数100万点以上ともいわれる江戸期以前のくずし字で記されている古典籍は、専門家による判読が必要とされ、テキストデータ化が遅れていた」と説明している。今回の新たなOCR技術開発により、専門家に依頼した場合と比べて大幅なコスト削減と、大量処理が可能になるとしている。
同社では、今夏から同OCR処理技術を使った古典籍のテキストデータ化サービスを試験的に開始する予定。
関連記事
 毎分250ページ、東大とDNPが共同開発した非破壊型高速ブックスキャナーとは?
毎分250ページ、東大とDNPが共同開発した非破壊型高速ブックスキャナーとは?
2010年に始まった、東京大学 石川渡辺研究室と大日本印刷による高速ブックスキャナーの共同開発。電子書籍の未来を担うかもしれないこの高速ブックスキャナーについて、DNPの開発担当者と渡辺義浩講師に話を伺った。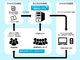 国立国会図書館、日本点字図書館と共同で視覚障害者を対象とした図書製作プロジェクトをスタート
国立国会図書館、日本点字図書館と共同で視覚障害者を対象とした図書製作プロジェクトをスタート
国立国会図書館デジタルコレクションに収録されている資料を用いて「テキストDAISY図書」と呼ばれるテキストデータを制作するとともに、テキスト化システムの活用可能性なども検証する。 自分でスキャンしたファイルをKindle本に変換できるAmazon謹製ソフトが登場
自分でスキャンしたファイルをKindle本に変換できるAmazon謹製ソフトが登場
ただし北米のみ。日本での展開は簡単ではなさそうだ。 障害者差別解消法と公共図書館――電子図書館サービスへの期待とは
障害者差別解消法と公共図書館――電子図書館サービスへの期待とは
2016年4月に施行予定の障害者差別解消法は、電子図書館サービスにどう影響するのか。図書館総合展で開催されたフォーラムからお届けする。- PocketBook、カメラ+OCRアプリ内蔵の電子書籍端末「Ultra」を来月発売?
意欲的な製品を世に送り出すPocketBook。今度はカメラとOCRアプリを内蔵した電子書籍リーダー端末が登場しそうです。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。